Market Research and Big Data: A Difficult Relationship
My advice to the market research world is to stop conceptualizing so much when it comes to Big Data and Data Science and simply apply the new techniques there where appropriate.
by Istvan Hajnal
Insights Director & Marketing & Data Sciences at GfK
0
By Istvan Hajnal
This is a write up of the talk I gave on the ‘Insight Innovation eXchange Europe 2015‘ conference on 18-02-2015 in Amsterdam. IIeX is a conference that is focused around Innovation in Market Research.My talk was a rather general one in which I tried to sketch the relationship between market research and big data. After a brief introduction, I started by explaining how computing played an important role in Market Research right after the second world war. Then I gave an overview of the current state, and finally I looked at what the future might bring us when it comes to Big Data applications in Market Research.
When I talk to people in market research and I tell them that I work in Big Data I have the impression that I’m greeted with less enthusiasm than was the case a few years a go. Indeed, it appears that the initial enthusiasm for Big Data in the Market Research community has dwindled down a bit.
I like to describe the relationship between market research and big data with The Three Phases of A Narcissistic Relationship (See The Three Phases of A Narcissistic Relationship Cycle: Over-Evaluation, Devaluation, Discard by Savannah Grey). A narcissist will choose a victim who is attractive, popular, rich or gifted. They will then place the target on a pedestal and worship them. The target is seen as the greatest thing ever. Here the Narcissist is ecstatic, full of hopes and dreams. They will talk and think about them constantly, they are euphoric. Now I’m not going to say that market research people where ecstatic and full of dreams when it came to big data, but you will have to admit that the initial enthusiasm for big data was especially high amongst market researchers.
But the narcissist is easily bored. The attention they gave to their target is gone and is replaced by indifference. This is the devaluation phase. The narcissist becomes moody, easily agitated, starts to blame and criticize the target. In the market research world, after a while, we saw a larger amount of papers that were quite critical with regard to Big Data. Big Data was often blamed for stuff we are not so good at ourselves (bad sampling, self-selection, dodgy causality).
Finally, in the Discard phase, the narcissist pulls away and starts to devote attention to its next victim, such as Neuromarketing, Internet of Things, and what have you.
Now of course I realize that this story is purely anecdotical, and has no scientific value. All I want to do here is to illustrate the tendency of Market Research to cherry pick innovations in other domains and apply it as a novelty in Market Research and then move on to the next darling.
The ‘old’ days
Now let me show you an example of true innovation in Market research, albeit from a long time a go. For that, I need to take you to the streets of Chicago in the 1940’s, where a young man was thinking about how he could help his father’s business become more efficient. His father, Arthur Nielsen Senior, had devised this methodology where he would sample stores in the U.S., and send out people to those stores to measure the stock levels of the products in the stores and look at the purchase invoices. By a simple subtraction rule and projecting up to the population he could reasonably estimate sales figures. Back in the forties there were no computers in private companies yet. They just started to emerge in the army and in some government administrations. In those days it was not unusual to see a team of human calculators who did the number crunching.
I can’t read the mind of the son, Arthur Nielsen Junior, but I can imagine that he must have said to himself while looking at his dad’s calculation team:
Hmm, Volume seems to be high here. And so is the Velocity.
Indeed, in those days they were doing this every two months. This is slow by today’s standards, but it was fast in the 1940’s. I can only speculate, but I like to think that he also added:
Hmm, luckily we’re doing OK on Variety and Veracity. Otherwise we would have to talk about the 4 V’s of Human Calculators.
Back on a more serious note, Arthur Junior was in the army during the war and there he had seen that the army deployed computers to crack the encrypted messages of the Germans. He convinced his dad’s company to invest a large amount of money in these new machines. Not many people outside of market research know this, but it was a market research company that was the first private company to ever order a computer. OK, I must admit the first order was in fact a tie with Prudential, and that first order might not have led to the first deployment of a computer in a private company (I believe the order got postponed at some point), but the important point here is the vision that these new machines would be useful in market research.Let me give you a second example. PL/1 stands for Programming Language 1 and is, as the name indicates, one of the first programming languages. It got introduced in the 60’s. The first versions of SAS were written in PL/1 and its DATA STEP has a bit of a PL/1 flavour to it. One of my current clients in the financial area still runs PL/1 in production, so it’s still around today. Well, Nielsen UK was the 6th company in that country to adopt this new language. Market researchers in those days were true pioneers. We tend to forget that a little bit.
Big Data Analytics in Market Research Today
According to GreenBook GRIT-report Market Research is doing quite well in Big Data.
More than 35%, both of clients and suppliers, have used Big Data Analytics in the past. But notice that this includes those that have done a one-off experiment. Secondly, the ambiguous definition of Big Data might have played a role as well. If we look at those that consider it, we see that that percentage for clients is a bit higher than with the suppliers.
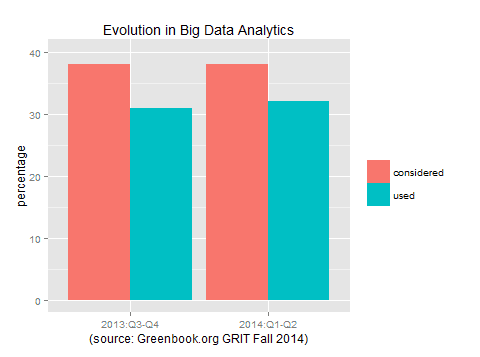
What about evolution?
Let’s compare the second half of 2013 with the first half of 2014. In terms of using Big Data Analytics we see a very small increase and in terms of considering it, there is no increase at all. We seemed to have plateaued here, albeit at at a high level.
In terms of papers and articles this list is more anecdotical than representative, but titles such as ‘The promise and the peril if Big Data’ illustrate the mixed feelings we seem to have.
In other words, market research seems to be bipolar when it comes to Big Data. We want to be part of the game, but we’re not really sure.
<
My advice to suppliers of market research
Don’t look at Big Data as just a fad or hype. By treating it as a fad we will miss an opportunity (and revenue) to answer questions our clients have. The hype will go, but the data will not go away!
Don’t look at Big Data as a threat to Market Research. It’s not. Very often we already have a foot in the door. Very often we are seen as the folks who know how to deal with data. If we decline, other will players move in. Yes, in some sectors we might have lost some ground, especially to consultancy firms, Business Intelligence folks and companies with a strong IT background.
But embrace it as a new (business) reality and learn how to process large amounts of structured and unstructured data.
The latter, learning how to process large amounts of data, is not difficult, and it doesn’t have to be expensive. You can already do a lot with R on a reasonably priced system and parallelize if need be, if you want to stay away from the typical Big Data Platforms, such as Hadoop.
Distributed storage and processing
But in fact we should not shy away from those new platforms. Again, it’s (relatively easy) and it’s, in principle, cheap. Any reasonably sized market research company with a few quants should at least consider it.
Hadoop takes care of distributed storage and distributed processing on clusters of commodity hardware. The storage part is called HDFS, The processing part is based on Map Reduce. I’m sure a lot of you have heard about Map-Reduce, but for those of you who have not, let me give a quick recap. Map Reduce is a strategy to run algorithms in parallel on a cluster of commodity hardware.
Let’s take the example a making hamburgers. I got the following figure from Karim Douïeb.
Imagine you have plenty of ingredients and a lot of kitchen personnel. What you don’t have is a lot of time. People are waiting for their burgers. Furthermore, you have a rather small kitchen, say you only have one place to panfry the burgers. One approach would be to assign one person in the kitchen per order and let them individually slice the ingredients, fry the meat for their burger, assemble it and serve it. This would work, but you quickly would get a queue at the frying pan, and your throughput of burgers would suffer.
An alternative approach is to assign one person in the kitchen per ingredient and have them slice or fry it. One or more other persons would pick up the required number of slices per ingredient, assemble it and serve the burgers. This approach would substantially increase the throughput of hamburgers, at the cost of a bit more coordination. The folks who do the slicing or frying are called the Mappers, the persons who are assembling the burgers and serve it, are called the Reducers. In Hadoop, think about data rather than ingredients, and about processors (CPU’s) rather than kitchen personnel.
The trick is thus to try and express your algorithm in this map and reduce framework. This may require programming skills and detailed knowledge of the algorithms that might not be available in your quant shop. Luckily there are some tools that shield the Map and Reduce for you. For instance you can access HDFS easily with SQL (Impala, Hive, …). If you have folks in your team who can program in, say SAS, where they might already use PROC SQL today, they will have no problem with Impala or Hive.
Another approach is to use R to let your quants access the cluster. It works relatively well, although it needs some tweaking.
The new kid on the block is Spark. Spark does not require you to write barebones Map Reduce jobs anymore. It is sometimes hailed as the successor to Hadoop, although they often co-exist in the same environment. Central to Spark is the Resilient Distributed Dataset (RDD) which allows you to work more in-memory than traditionally, it abstracts some of the Map/Reduce steps for you, and it generally fits better with traditional programming styles. Spark allows you to write in Java, Scala or Python (and soon R as well). With SparkSQL it has an SQL-like interface, Spark Streaming allows you to work in real-time rather than in batch. There is a Machine Learning library, and lots of other goodies.
Tools such as Hive, R and Spark make distributed processing within reach of market researchers.
Trends
There are few trends in the Big Data and Data Science world that can be of interest to market researchers:
Visualization. There is a lot of interest in the Big Data and Data Science world for everything that has to do with Visualization. I’ll admit that sometimes it is Visualize to Impress rather than to Inform, but when it comes to informing clearly, communicating in a simple and understandable way, storytelling, and so on, we market researchers have a head start.
Natural Language Processing. One of the 4 V’s of Big Data stands for Variety. Very often this refers to unstructured data, which sometimes refers to free text. Big Data and Data Science folks, for instance, start to analyze text that is entered in the free fields of production systems. This problem is not dissimilar to what we do when we analyse open end questions. Again market research has an opportunity to play a role here. By the way, it goes beyond sentiment analysis. Techniques that I’ve seen successfully used in the Big Data / Data Science world are topic generation and document classification. Think about analysing customer complaints, for instance.
Deep Learning. Deep learning risks to become the next fad, largely because of the name Deep. But deep here does not refer to profound, but rather to the fact that you have multiple hidden layers in a neural network. And a neural network is basically a logistic regression (OK, I simplify a bit here). So absolutely no magic here, but absolutely great results. Deep learning is a machine learning technique that tries to model high-level abstractions by using so called learning representations of data where data is transformed to a representation of that data that is easier to use with other Machine Learning techniques. A typical example is a picture that constitutes of pixels. These pixels can be represented by more abstract elements such as edges, shapes, and so on. These edges and shapes can on their turn be further represented by simple objects, and so on. In the end, this example, leads to systems that are able to reasonably describe pictures in broad terms, but nonetheless useful for practical purposes, especially, when processing by humans is not an option. How can this be applied in Market Research? Already today (shallow) Neural networks are used in Market Research. One research company I know uses neural networks to classify products sold in stores in broad buckets such as pet food, clothing, and so on, based on the free field descriptions that come with the barcode data that the stores deliver.
Conclusion
My advice to the market research world is to stop conceptualizing so much when it comes to Big Data and Data Science and simply apply the new techniques there where appropriate.
The views, opinions, data, and methodologies expressed above are those of the contributor(s) and do not necessarily reflect or represent the official policies, positions, or beliefs of Greenbook.
Comments
Comments are moderated to ensure respect towards the author and to prevent spam or self-promotion. Your comment may be edited, rejected, or approved based on these criteria. By commenting, you accept these terms and take responsibility for your contributions.
Why are we still measuring brand loyalty? It isn’t something that naturally comes up with consumers, who rarely think about brand first, if at all. Ma...